
PiFlow-����ˮ��ϵ�y-PiFlow���d v0.9�ٷ��汾
- ܛ����ͣ��W�jܛ��
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2023-08-30
- ��x������
- ���]�Ǽ�:
- �\�Эh����WinXP,Win7,Win10,Win11
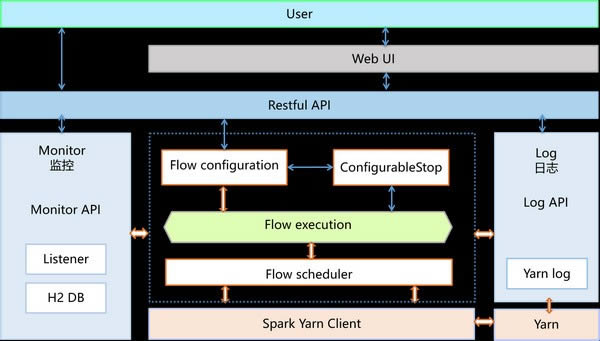
PiFlow��һ���������ã�������Ĵ���ˮ��ϵ�y������ͿƌW����ˮ��ϵ�y�������S����̎�����M�����ṩShell��DSL��Web���ý��桢�΄��{�ȡ��΄ձO�صȹ��ܣ�
PiFlow��ɫ
��������
��ҕ��������ˮ��
�O����ˮ��
�鿴��ˮ����־
�z���c����
�Uչ�ԏ�:
֧���Զ��x�_�l����̎���M��
���܃�Խ��
���ڷֲ�ʽӋ������Spark�_�l
������
�ṩ100+�Ĕ���̎���M��
����Hadoop ��Spark��MLlib��Hive��Solr��Redis��MemCache��ElasticSearch��JDBC��MongoDB��HTTP��FTP��XML��CSV��JSON��
�����������I������P�㷨
PiFlowʹ�÷���
�≺piflow-server-v0.9.tar.gz:
tar -zxvf piflow-server-v0.9.tar.gz
�������ļ�config.properties
�\�С�ֹͣ���؆�PiFlow Server
start.sh��stop.sh�� restart.sh�� status.sh
�yԇ PiFlow Server
�O�íh��׃�� PIFLOW_HOME
vim /etc/profile
export PIFLOW_HOME=/yourPiflowPath/bin
export PATH=PATH:PIFLOW_HOME/bin
�\����������
piflow flow start example/mockDataFlow.json
piflow flow stop appID
piflow flow info appID
piflow flow log appID
piflow flowGroup start example/mockDataGroup.json
piflow flowGroup stop groupId
piflow flowGroup info groupId
�������config.properties
#spark and yarn config
spark.master=yarn
spark.deploy.mode=cluster
#hdfs default file system
fs.defaultFS=hdfs://10.0.86.191:9000
#yarn resourcemanager.hostname
yarn.resourcemanager.hostname=10.0.86.191
#if you want to use hive, set hive metastore uris
#hive.metastore.uris=thrift://10.0.88.71:9083
#show data in log, set 0 if you do not want to show data in logs
data.show=10
#server port
server.port=8002
#h2db port
h2.port=50002