���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C�f�ܰ����d

��Tesseract OCR���d��Tesseract OCR�DƬ�����R�eܛ�� v4.0 ���M��
- ܛ����ͣ��k��ܛ��
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2025-02-09
- ��x��(sh��)����
- ���]�Ǽ�:
- �\�Эh(hu��n)����WinXP,Win7,Win10,Win11
ܛ����B
Tesseract OCR��һ���_Դ��ocr���棬Ҳ���Կ����LjD�������R�e����������Ҫ���ܾ��ǎ����ÑDƬ�е����փ����R�e�������������D�Q���ı���Tesseract OCRʹ�������ܷ��㣬���H�R�e�ʴ_�ʸߣ������R�e���ٶ�Ҳ�ܿ죬����Ҫ���Ñ�������d�ɡ�
ʹ�ý̳�
���w���̣�Tesseract���b -> ���_������ -> ����Ŀ���ļ�
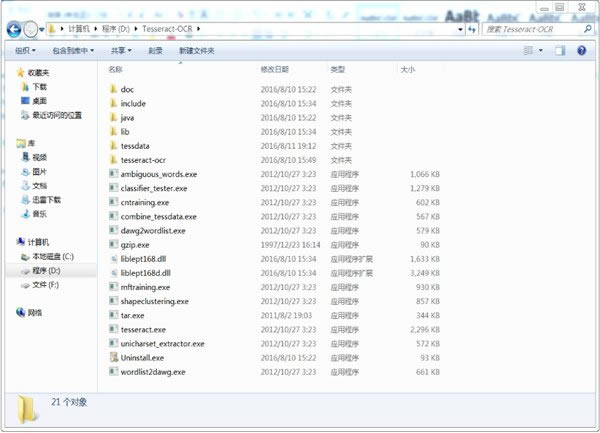
Tesseract���b
���d���b�������b�ɹ�����������űP����Tesseract-OCR�ļ��A����D
���_������
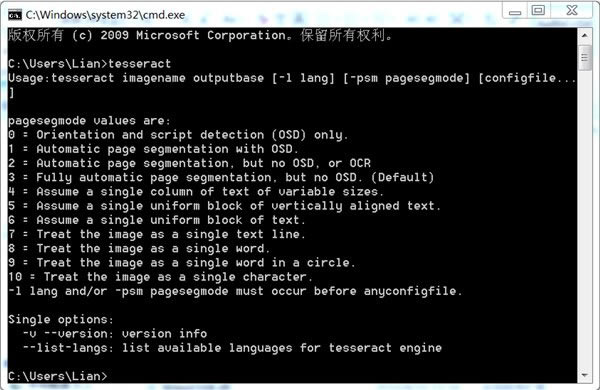
���_�����У�ݔ��tesseract����܇;���±���tesseract�Ĵ��w��ò��
����Ŀ���ļ�
�Ȝʂ�һ���DƬ�ļ�����test.png
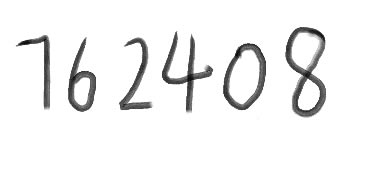
���������ГQ��Ŀ�ˈD���ļ�Ŀ䛣������҂��D�Q�ļ���test.png(�DƬ�ļ����S��N��ʽ)��λ��C:\Users\Lian\Desktop\test;Ȼ������������ݔ��
tesseract test.png output_1 –l eng
���Z����: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename��Ŀ�ˈDƬ�ļ�������Ӹ�ʽ��Y;outputbase���D�Q�Y���ļ���;lang���Z�����Q(��Tesseract-OCR��tessdata�ļ��A�ɿ�����eng�_�^���Z���ļ�eng.traineddata)���粻��-l eng�tĬ�J��eng��

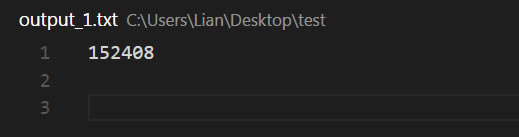
���_�ļ�output_1.txt���l(f��)�F(xi��n)tesseract�ɹ��Č��D���D�Q�� 152408 ��
1�M���ƽ̌Wͨ2.0-�M���ƽ̌Wͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3��Ѹ��Ӳ��v����ܛ��-��Ѹ��Ӳ��v����ܛ�����d ......
4���vӍ����ģ�M���Gɫ�����d���vӍ����ģ�M���Gɫ��......
5��Ք�(sh��)�W��X�˹ٷ�����2024���°�Gɫ���M���d......
6Archbeeܛ���ṩ���d-Archbee�͑���......
7�ٶȾW(w��ng)�P��ˬ����������-�W(w��ng)�P����-�ٶȾW(w��ng)�P��ˬ��......
8360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
1����\��GHOST���bϵ�y(t��ng),��������\���R���b�C
2ϵ�y(t��ng)֮��һ�IU�P���bwindows7ϵ�y(t��ng)�D��Ԕ��...
3Ů����ɶ���^��ã��m��Ů���\�õ����^��_��
4���Ľ�����ΰ��bghostxpϵ�y(t��ng)
6Windows��������Win10ʧ����ʾ0x80...
7����Windows10 1607�汾�ľ��w�O�÷�...
8win10��X�桶ֲ����(zh��n)��ʬ���W�˵�̎���k��